

上个月,中国公司DeepSeek推出一款新的人工智能(AI)模型,使用不怎么先进的芯片和少得多的处理能力就实现了可匹敌美国竞争对手模型的性能,这在华尔街引发了冲击波。
DeepSeek发表的一篇论文显示,该公司之所以能少花钱、多办事,是因为其最新的R1模型更多地依赖“强化学习”,在这种过程中,模型使用为自己创建和调整的奖励系统,从自身行动中获得反馈。
该模型首先从现有的文本库开始,这些文本被分解成独特的单词、词语片段和标点符号,然后可以以不同的方式重新组合在一起。这种“大语言模型”拥有超过6,710亿个可调整的设置,称为“参数”,可以通过调整这些参数来决定模型如何响应提示。
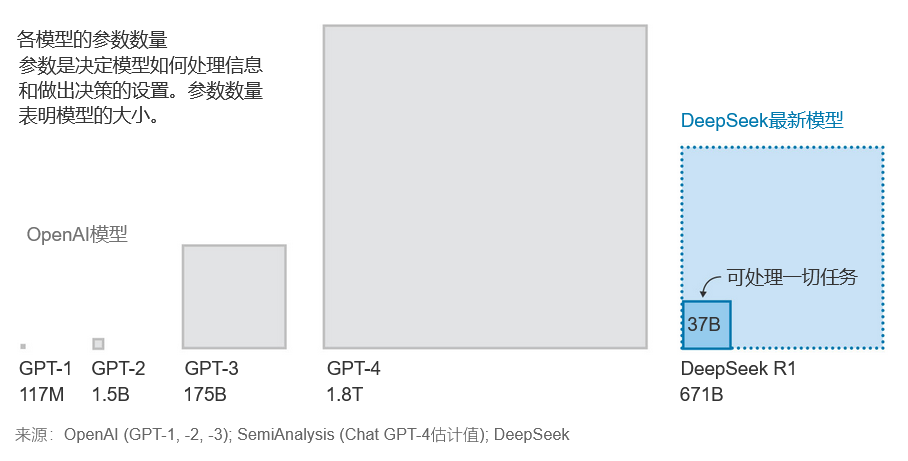
参数数量是衡量模型规模的一种方式。与传统的AI模型不同,在任何一次操作中,R1的可调整设置只有一小部分处于活动状态。活动参数的减少大大降低了处理所需的能耗和计算量,使模型能在成本更低、不那么复杂的芯片上运行。
DeepSeek R1模型的工作原理是分成多个具有不同专长的网络,这种方法被称为“混合专家”。某些提示将需要不同的专业知识,该模型将只调用其认为最相关的网络用以回答提示。
相比之下,传统的AI模型在名为“监督训练”的过程中依赖于大量预先标记的数据集。预先标记是由人工完成的,既昂贵又耗时。
DeepSeek模型的另一个独特之处在于它是开源的,这意味着它可以被公司外部的开发人员重新利用。
在加州大学伯克利分校(University of California, Berkeley)研究人员运营的评估AI模型的平台Chatbot Arena上,DeepSeek R1模型的排名接近榜首。
对于数学和写代码等任务,R1的表现优于大多数其他模型。
依据Chatbot Arena评分排名的顶级AI模型,包括总得分和不同任务分类得分
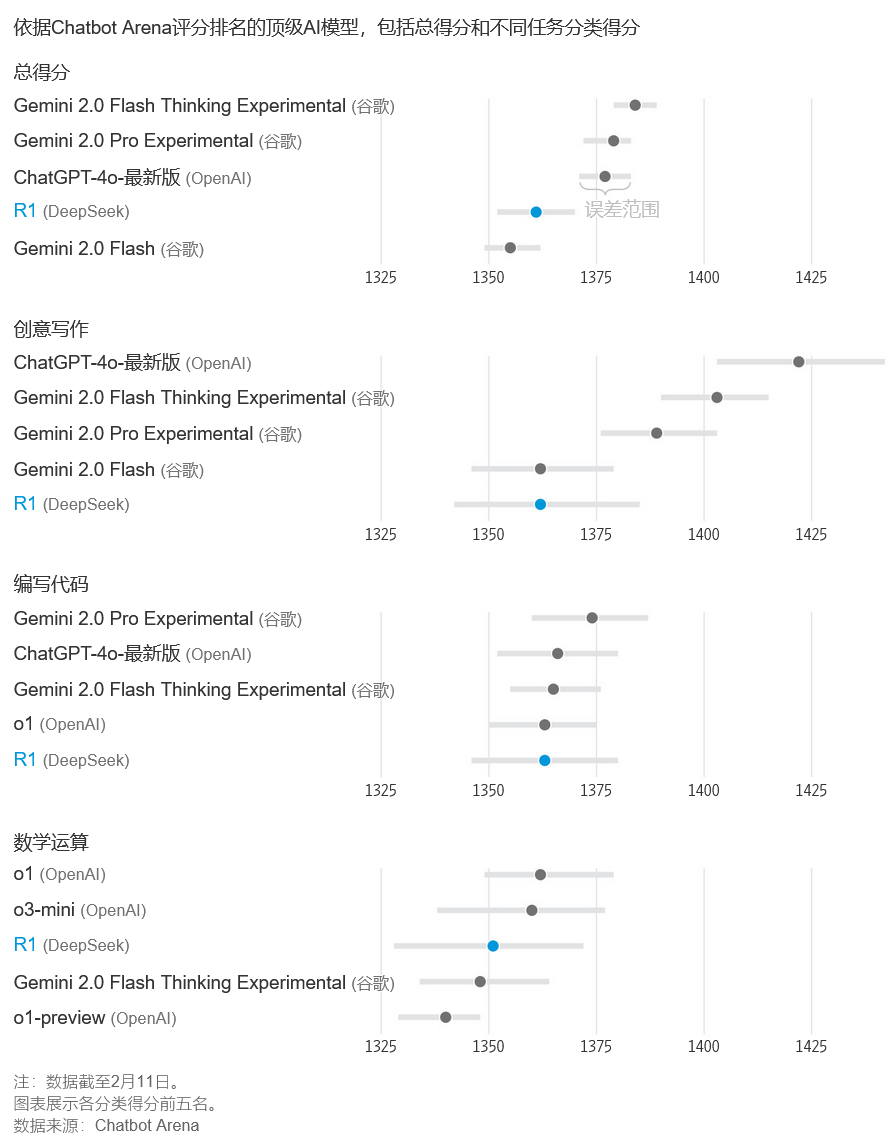
Chatbot Arena的数据来自访问其网站的访问者,他们提出问题,从两个匿名的AI模型中获得答案,然后对哪个模型更好进行评分。该网站已对大约200个模型进行了超过250万次投票。
根据AI基准分析公司Artificial Analysis汇编的数据,DeepSeek对开发人员访问R1的定价低于其智能级别中的许多其他模型。
AI模型的制造商根据双方之间来回发送的数据量,或行业术语中的“基本单元”(token)数量,向希望将该技术集成到其产品中的企业等用户收费。
顶级AI模型的定价与质量
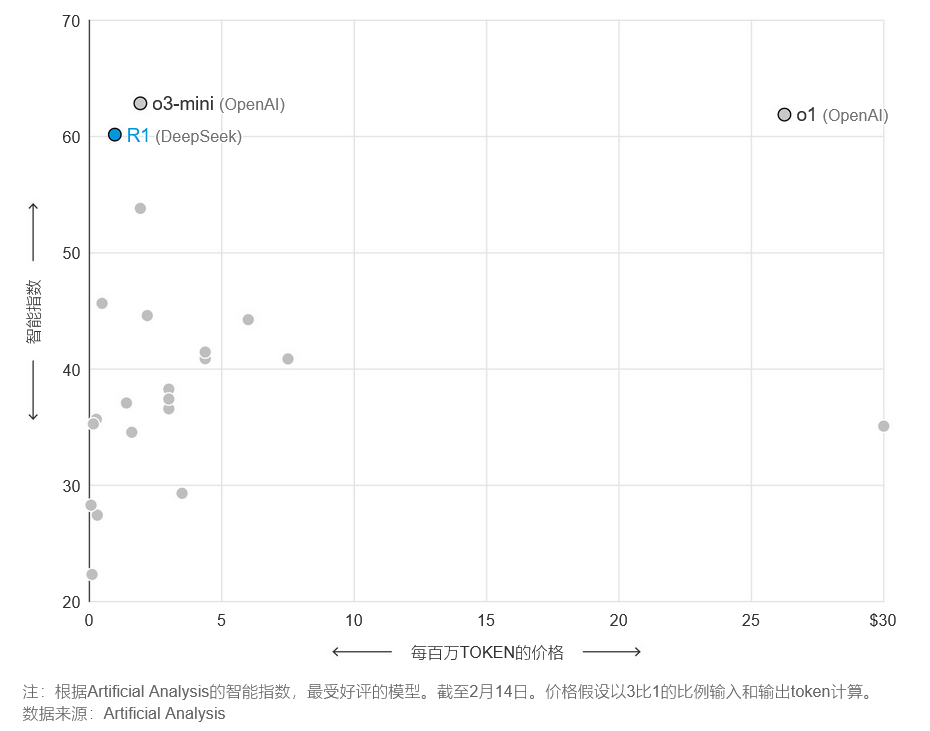
注:根据Artificial Analysis的智能指数,最受好评的模型。截至2月14日。价格假设以3比1的比例输入和输出token计算。数据来源:Artificial Analysis
文章来自华尔街日报
文章末尾固定信息
